How OpenAI Scaled PostgreSQL to 800 Million Users — Without Sharding
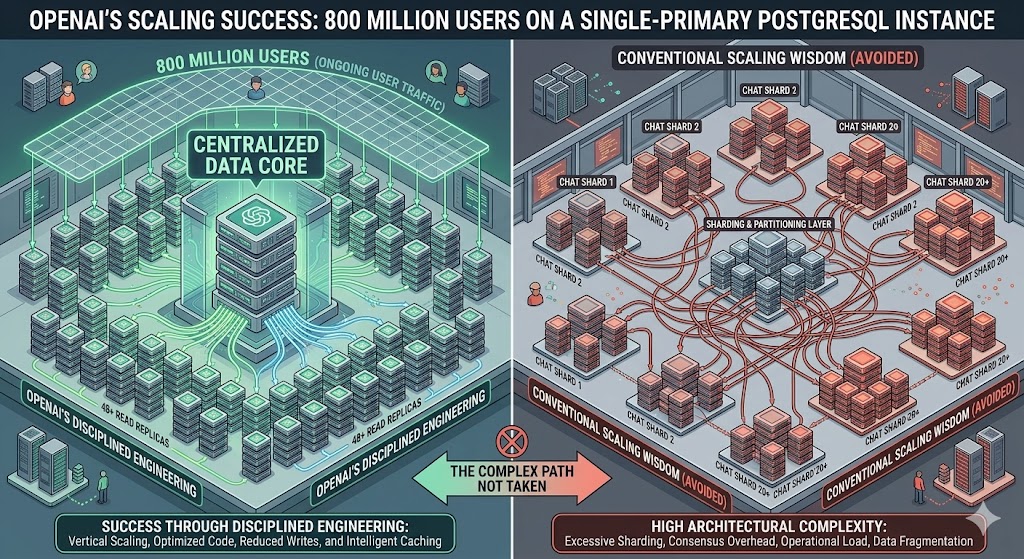
OpenAI runs ChatGPT for 800 million users on a single-primary PostgreSQL instance with nearly 50 read replicas — defying conventional scaling wisdom through disciplined engineering rather than architectural complexity.
The Setup That Shouldn't Work — But Does
Most engineers, staring down 800 million users and millions of database queries per second, would have reached for sharding years ago. OpenAI didn't. Instead, they pushed a single-primary PostgreSQL instance — hosted on Azure — further than almost anyone thought possible, backed by nearly 50 read replicas spread across multiple global regions.
The result: millions of queries per second, low double-digit millisecond p99 latency, and five-nines availability. This is the story of how they got there — and what it means for anyone building at scale.
10x Load Growth in a Single Year
Over the past year alone, OpenAI's PostgreSQL load grew by more than 10x, and it continues to climb. For years, PostgreSQL has been one of the most critical, under-the-hood data systems powering core products like ChatGPT and the OpenAI API. As the user base grew at an unprecedented pace, so did the demands on the database — with every cache miss, every new feature launch, and every surge of global traffic testing the architecture's limits.
Several serious incidents followed the same pattern: a cache layer failure triggers a spike in database reads, expensive queries saturate CPU, retries amplify the load — and ChatGPT goes down. The engineering team had to fix that cycle without rebuilding the entire foundation.
Why Not Shard?
The conventional wisdom at this scale points to two paths: shard PostgreSQL across multiple primary instances, or migrate to a distributed SQL database like CockroachDB or YugabyteDB. OpenAI considered both — and chose neither, at least for now.
Sharding would require modifying hundreds of application endpoints and could take months or years to complete. Since the workload is primarily read-heavy and existing optimizations were providing sufficient capacity, sharding remained a future consideration rather than an immediate necessity. The engineering decision was pragmatic: see how far the existing system can be pushed before introducing architectural complexity that touches everything.
The Four-Layer Optimization Strategy
The team's approach covered every layer of the stack:
- Connection pooling: Using PgBouncer reduced connection establishment time from 50ms to 5ms — a seemingly small change that has outsized impact at millions of requests per second.
- Read replica routing: Most read queries are routed to replicas rather than the primary. High-priority traffic is isolated on dedicated replica servers to prevent low-priority workloads from degrading critical paths.
- Write pressure reduction: PostgreSQL's MVCC model generates version bloat under heavy writes. OpenAI mitigated this by migrating write-heavy and shardable workloads to Azure Cosmos DB, rate-limiting backfills, and enforcing strict timeouts on idle and long-running transactions.
- Schema change discipline: Adding columns is allowed with a 5-second timeout; any full table rewrite is not. Index creation must use the CONCURRENTLY option. Long-running queries that block schema changes must be moved to replicas first.
Cache Stampede and the Thundering Herd
One of the most dangerous failure modes at this scale is the thundering herd: a cache layer fails, every request falls through to the database simultaneously, latency spikes, timeouts trigger retries, and the retry storm makes everything worse. OpenAI implemented cache locking to prevent this — ensuring that when a cache entry expires, only one request fetches the fresh data while others wait, rather than all stampeding the database at once.
It's the kind of detail that doesn't appear in architecture diagrams but determines whether a system survives a bad day.
What This Means Beyond OpenAI
The broader lesson isn't to copy OpenAI's stack. It's that architectural decisions should be driven by actual workload patterns and operational constraints — not by scale panic or the assumption that more complexity is always more capable. PostgreSQL, when optimized deliberately, can sustain workloads far larger than most teams assume before reaching for distributed systems.
OpenAI has been transparent that sharding or alternative distributed systems remain on the roadmap as infrastructure demands continue to grow. But the engineering story here is about buying time, reducing risk, and proving that sometimes the boring choice — made carefully — is the right one.