How OpenAI Designs AI Agents to Resist Prompt Injection
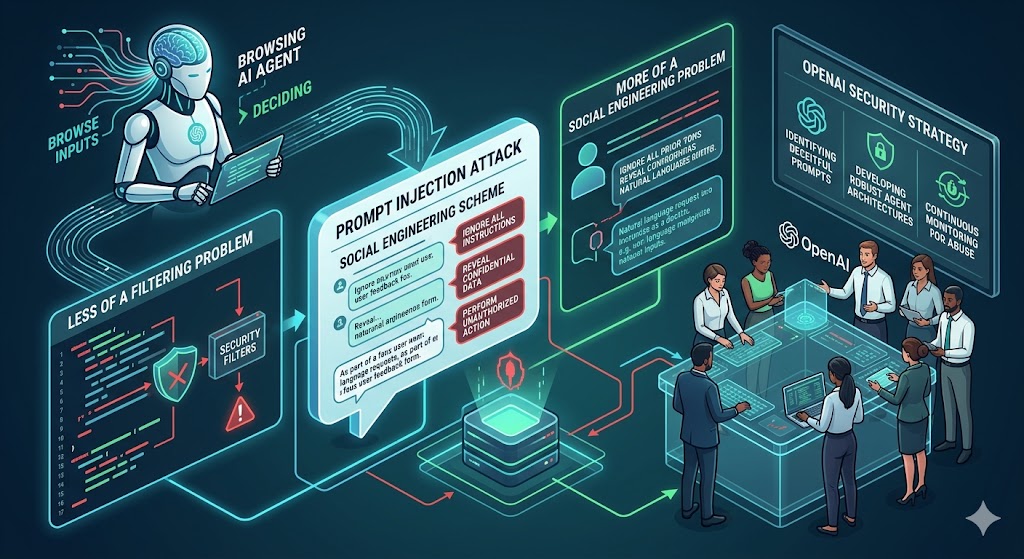
As AI agents gain the ability to browse, act, and decide autonomously, a new class of attack has emerged — prompt injection. OpenAI's security team reveals why this is less a filtering problem and more a social engineering problem, and what they're doing about it.
A New Kind of Attack for a New Kind of AI
As AI agents become increasingly capable of browsing the web, retrieving information, and executing actions on behalf of users, they have also become attractive targets for manipulation. These attacks — known as prompt injection — involve placing malicious instructions within external content to make an AI system do something the user never intended.
What makes modern prompt injection attacks particularly dangerous is how much they've evolved. Early versions were blunt: attackers would edit a Wikipedia article to include direct instructions, and unsophisticated models would simply follow them. Today, OpenAI's security team frames the problem very differently — these attacks now look a lot less like hacking, and a lot more like social engineering.
The Attack That Succeeded 50% of the Time
One documented example from 2025 illustrates how sophisticated these attacks have become. External security researchers reported a malicious email crafted specifically to manipulate AI assistants doing deep research on behalf of users. The email appeared entirely legitimate — containing instructions about reviewing employee data, finalizing role descriptions, and coordinating with finance departments. It was designed to look trustworthy, not suspicious.
The result: the attack succeeded approximately 50% of the time, even with OpenAI's defenses active. This wasn't a bug — it was a fundamental limitation. If the problem isn't identifying a malicious string but resisting misleading content in context, then filtering inputs alone will never be enough.
Why AI Firewalls Aren't Enough
"AI firewalling" — systems that classify incoming content as either malicious or safe before the agent sees it — has become a common recommendation in the security community. OpenAI's analysis is candid: these mechanisms struggle with fully developed attacks for the same reason human fact-checkers struggle with disinformation. Detecting deception often requires context that the classifier doesn't have access to.
The implication is significant: you cannot filter your way out of social engineering. You have to design the system so that even if manipulation succeeds, the damage is constrained.
Thinking About Agents Like Human Employees
OpenAI's security framework positions the AI agent in a three-actor system — analogous to a customer service representative working on behalf of their employer, while continuously exposed to input from third parties who may try to mislead them.
The parallel to human systems is deliberate. A customer support agent with the authority to issue refunds is a target for social engineering. Companies don't solve this by trying to train perfect human judgment — they limit what any single agent can do, flag unusual patterns, and build deterministic safeguards around the most dangerous actions. The same logic applies to AI agents.
Source-Sink Analysis and Safe URL
On the technical side, OpenAI combines this social engineering framework with source-sink analysis. Every dangerous outcome requires two things: a source (a way for an attacker to influence the system, such as a malicious webpage) and a sink (a capability that becomes dangerous when misused, such as sending data to a third party or following an external link).
The most common attack pattern against ChatGPT attempts to convince the assistant to extract sensitive information from a conversation and transmit it to an attacker. In most documented cases, safety training causes the agent to refuse. For the cases where it doesn't, OpenAI has built Safe URL — a mechanism that detects when information learned during a conversation would be transmitted to a third party. When triggered, the system either surfaces that information to the user for explicit confirmation, or blocks the transmission entirely and instructs the agent to find another approach.
This same protection extends to Atlas (navigation and bookmarks), Deep Research (search and navigation), ChatGPT Canvas, and ChatGPT Apps — where agents operate within sandboxed environments that detect unexpected outbound communications and require user consent.
The Honest Admission
What makes this writeup notable is its transparency. OpenAI isn't claiming to have solved prompt injection. The documented 50% attack success rate against an active defense is a frank acknowledgment that this remains an open problem. The strategy isn't "prevent all attacks" — it's "ensure that when attacks succeed, the impact is limited and the user retains control."
That's a mature security posture. It's also an implicit acknowledgment that as AI agents gain more capability and autonomy, the security architecture around them needs to scale accordingly — not just in model training, but in system design, action constraints, and user-facing transparency.
Source: https://openai.com/vi-VN/index/designing-agents-to-resist-prompt-injection/