How OpenAI Stops AI Agents From Quietly Leaking Your Data Through URLs
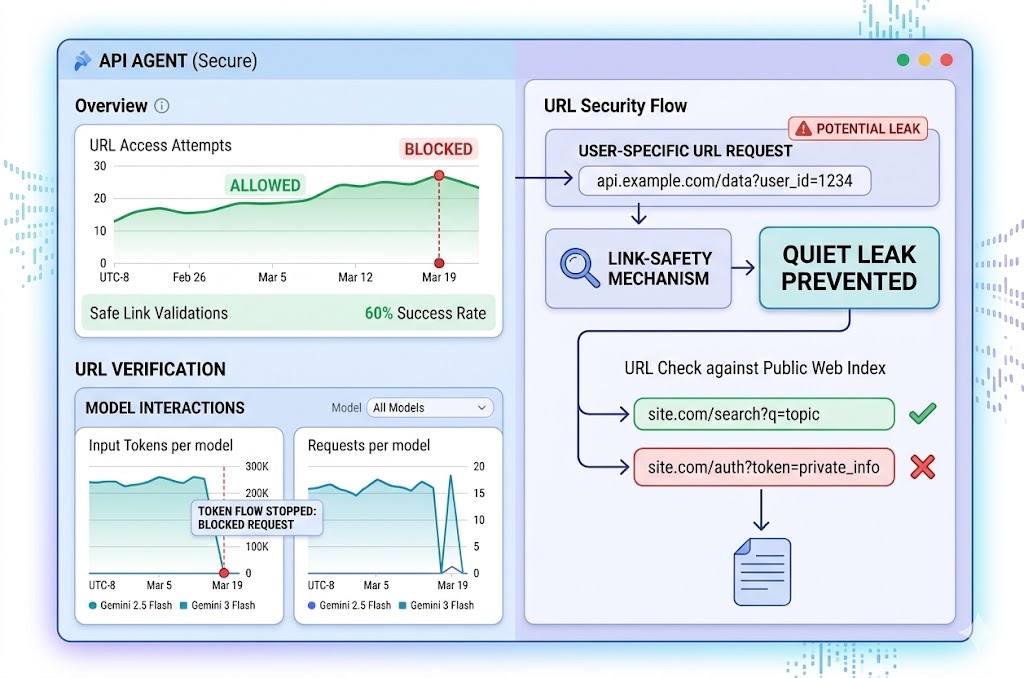
OpenAI has shipped a link-safety mechanism for ChatGPT that prevents agents from automatically fetching URLs that could contain user-specific data. The system verifies links against a public web index before loading them — blocking the 'quiet leak' scenario where sensitive information escapes through query strings.
The Threat Most People Don't See
When an AI agent loads a link, the full URL—including query parameters—is sent to the destination server and often logged. Attackers can prompt an agent to include sensitive context like email content or document titles in that URL, creating a silent leak even via redirects, embedded images, or link previews. The user doesn't see it happening. The data just leaves.
This isn't hypothetical. It's one of the most reliably exploitable paths in agentic systems because it operates below the user's line of sight.
Why Simple Allow-Lists Don't Work
Many legitimate websites support redirects. A link can start on a "trusted" domain and immediately forward you somewhere else. If your safety check only looks at the first domain, an attacker can route traffic through a trusted site and end up on an attacker-controlled destination. Even worse, rigid allow-lists create friction — users get frequent false alarms and eventually learn to click through warnings without reading them.
OpenAI needed a different principle: not "this domain seems reputable," but "this exact URL is already publicly known."
The Core Mechanism
OpenAI uses an independent web index (separate from user conversations) to verify whether a URL is publicly known. If a URL is already known to exist publicly on the web, independently of any user's conversation, the system treats it as safe to fetch automatically. The logic is simple but powerful: if the URL already exists in the public index before the conversation began, it can't contain user-specific secrets embedded in query strings.
What Happens When a Link Isn't Verified
When a link can't be verified as public and previously seen, users see a warning: "The link isn't verified. It may include information from your conversation. Make sure you trust it before proceeding." This is the moment where the system hands control back to the user — precisely when an agent might otherwise load a URL without you noticing.
If something looks off, the safest choice is to skip the link and ask the model for an alternative source or summary.
What This Does and Doesn't Protect
These safeguards are aimed at one specific guarantee: preventing the agent from quietly leaking user-specific data through the URL itself when fetching resources. This defense focuses on URL-based exfiltration. It doesn't guarantee page trustworthiness or remove all prompt-injection risks — OpenAI layers it with model-level mitigations, product controls, monitoring, and red-teaming as part of a defense-in-depth approach.
The Broader Context: Agent Security in 2026
Attacks against ChatGPT most often consist of attempting to convince the assistant to take secret information from a conversation and transmit it to a malicious third-party. In most cases, these attacks fail because OpenAI's safety training causes the agent to refuse. But when that training layer doesn't catch it, link safety becomes the second line of defense.
OpenAI has acknowledged that prompt injection, much like scams and social engineering on the web, is unlikely to ever be fully "solved." Agent mode in ChatGPT expands the security threat surface. That's the honest admission: agentic systems introduce new attack vectors that don't have perfect solutions yet.
The Long Game
OpenAI's goal is for AI agents to be useful without creating new ways for information to "escape." Preventing URL-based data exfiltration is one concrete step in that direction, and the company will keep improving these protections as models and attack techniques evolve.
This isn't a silver bullet — it's a guardrail. But in a space where the threat model is still being mapped out in real time, guardrails matter. The bar for agent safety keeps rising, and features like link verification are how that bar actually moves.