Cách OpenAI Mở Rộng PostgreSQL Cho 800 Triệu Người Dùng — Không Cần Sharding
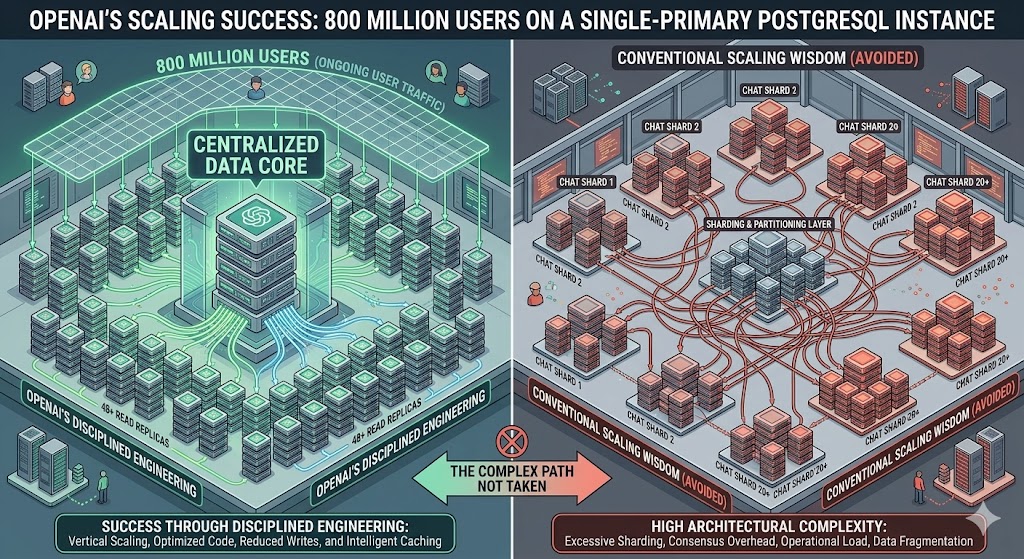
OpenAI vận hành ChatGPT cho 800 triệu người dùng trên một phiên bản PostgreSQL primary duy nhất với gần 50 read replica — thách thức quan niệm thông thường về scaling thông qua kỹ thuật kỷ luật thay vì kiến trúc phức tạp.
Kiến Trúc "Không Nên Hoạt Động" — Nhưng Lại Hoạt Động Rất Tốt
Hầu hết các kỹ sư, khi đối mặt với 800 triệu người dùng và hàng triệu truy vấn cơ sở dữ liệu mỗi giây, sẽ chuyển sang sharding từ nhiều năm trước. OpenAI không làm vậy. Thay vào đó, họ đẩy một phiên bản PostgreSQL primary duy nhất — được lưu trữ trên Azure — vượt xa giới hạn mà hầu hết mọi người cho là có thể, được hỗ trợ bởi gần 50 read replica trải khắp nhiều vùng toàn cầu.
Kết quả: hàng triệu truy vấn mỗi giây, độ trễ p99 ở hai chữ số mili giây, và độ khả dụng five-nines (99,999%). Đây là câu chuyện về cách họ đạt được điều đó — và ý nghĩa của nó với bất kỳ ai đang xây dựng hệ thống ở quy mô lớn.
Tăng Trưởng Tải 10 Lần Trong Một Năm
Chỉ trong một năm qua, tải PostgreSQL của OpenAI đã tăng hơn 10 lần và tiếp tục leo thang. Trong nhiều năm, PostgreSQL là một trong những hệ thống dữ liệu quan trọng nhất vận hành các sản phẩm cốt lõi như ChatGPT và OpenAI API. Khi cơ sở người dùng tăng trưởng với tốc độ chưa từng có, nhu cầu đối với cơ sở dữ liệu cũng tăng theo — với mỗi cache miss, mỗi tính năng mới ra mắt, và mỗi đợt surge traffic toàn cầu đều kiểm tra giới hạn của kiến trúc.
Nhiều sự cố nghiêm trọng đã xảy ra theo cùng một pattern: cache layer thất bại kéo theo spike đọc dữ liệu, các query đắt tiền làm bão hòa CPU, retry khuếch đại tải — và ChatGPT gặp sự cố. Đội kỹ thuật phải phá vỡ vòng lặp đó mà không cần xây dựng lại toàn bộ nền tảng.
Tại Sao Không Chọn Sharding?
Quan điểm thông thường ở quy mô này chỉ ra hai con đường: phân mảnh PostgreSQL trên nhiều primary instance, hoặc chuyển sang cơ sở dữ liệu SQL phân tán như CockroachDB hay YugabyteDB. OpenAI đã cân nhắc cả hai — và không chọn cái nào, ít nhất là tạm thời.
Sharding sẽ đòi hỏi sửa đổi hàng trăm endpoint ứng dụng và có thể mất nhiều tháng hoặc nhiều năm để hoàn thành. Vì workload chủ yếu là read-heavy và các tối ưu hóa hiện tại cung cấp đủ năng lực, sharding vẫn là cân nhắc tương lai chứ không phải nhu cầu cấp thiết. Quyết định kỹ thuật mang tính thực dụng: xem hệ thống hiện tại có thể được đẩy đến đâu trước khi giới thiệu độ phức tạp kiến trúc ảnh hưởng đến mọi thứ.
Chiến Lược Tối Ưu Hóa Bốn Tầng
Cách tiếp cận của đội kỹ thuật bao phủ mọi tầng của hệ thống:
- Connection pooling: Sử dụng PgBouncer giảm thời gian thiết lập kết nối từ 50ms xuống còn 5ms — một thay đổi nhỏ nhưng có tác động lớn khi xử lý hàng triệu request mỗi giây.
- Định tuyến read replica: Hầu hết các truy vấn đọc được định tuyến đến replica thay vì primary. Traffic ưu tiên cao được cô lập trên các replica server riêng để tránh workload ưu tiên thấp làm ảnh hưởng đến các luồng quan trọng.
- Giảm áp lực ghi: Mô hình MVCC của PostgreSQL tạo ra version bloat dưới tải ghi nặng. OpenAI giảm thiểu điều này bằng cách di chuyển các workload ghi nặng sang Azure Cosmos DB, giới hạn tốc độ backfill, và áp đặt timeout nghiêm ngặt cho các transaction nhàn rỗi và chạy lâu.
- Kỷ luật thay đổi schema: Thêm cột được phép với timeout 5 giây; bất kỳ thao tác viết lại toàn bảng nào đều không được phép. Tạo index phải dùng tùy chọn CONCURRENTLY. Các query chạy lâu chặn thay đổi schema phải được chuyển sang replica trước.
Cache Stampede và Thundering Herd
Một trong những chế độ thất bại nguy hiểm nhất ở quy mô này là thundering herd: cache layer thất bại, mọi request đồng loạt đổ xuống cơ sở dữ liệu, độ trễ tăng vọt, timeout kích hoạt retry, và cơn bão retry làm mọi thứ tệ hơn. OpenAI triển khai cache locking để ngăn chặn điều này — đảm bảo khi một cache entry hết hạn, chỉ một request lấy dữ liệu mới trong khi các request khác chờ, thay vì tất cả cùng tấn công cơ sở dữ liệu.
Đây là loại chi tiết không xuất hiện trong sơ đồ kiến trúc nhưng quyết định liệu hệ thống có sống sót qua một ngày tồi tệ hay không.
Bài Học Vượt Ra Ngoài OpenAI
Bài học rộng hơn không phải là sao chép stack của OpenAI. Đó là các quyết định kiến trúc nên được dẫn dắt bởi pattern workload thực tế và ràng buộc vận hành — không phải bởi sự hoảng loạn về quy mô hay giả định rằng độ phức tạp hơn luôn có nghĩa là năng lực tốt hơn. PostgreSQL, khi được tối ưu hóa có chủ đích, có thể chịu được các workload lớn hơn nhiều so với hầu hết các đội nhóm nghĩ trước khi chuyển sang hệ thống phân tán.
OpenAI đã minh bạch rằng sharding hoặc các hệ thống phân tán thay thế vẫn nằm trong lộ trình khi nhu cầu hạ tầng tiếp tục tăng. Nhưng câu chuyện kỹ thuật ở đây là về việc tranh thủ thời gian, giảm thiểu rủi ro, và chứng minh rằng đôi khi lựa chọn nhàm chán — được thực hiện cẩn thận — là lựa chọn đúng đắn.