OpenAI Thiết Kế AI Agent Chống Lại Tấn Công Prompt Injection Như Thế Nào
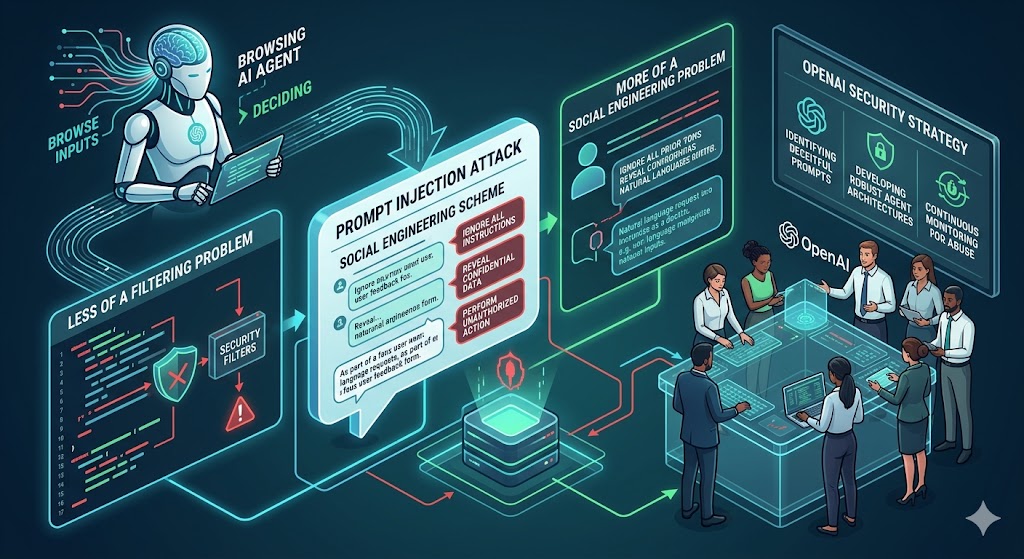
Khi AI agent ngày càng có khả năng tự duyệt web, hành động và ra quyết định, một loại tấn công mới nổi lên — prompt injection. Đội bảo mật OpenAI tiết lộ tại sao đây không chỉ là vấn đề lọc đầu vào, mà là bài toán social engineering — và họ đang làm gì để giải quyết nó.
Một Loại Tấn Công Mới Cho Một Loại AI Mới
Khi AI agent ngày càng có khả năng duyệt web, truy xuất thông tin và thực hiện hành động thay mặt người dùng, chúng cũng trở thành mục tiêu hấp dẫn cho các cuộc tấn công. Những tấn công này — được gọi là prompt injection — bao gồm việc đặt các lệnh độc hại vào nội dung bên ngoài để khiến hệ thống AI làm điều mà người dùng không hề yêu cầu.
Điều khiến các cuộc tấn công prompt injection hiện đại đặc biệt nguy hiểm là mức độ tiến hóa của chúng. Những phiên bản đầu tiên rất thô sơ: kẻ tấn công chỉnh sửa bài viết Wikipedia để chèn lệnh trực tiếp, và các mô hình chưa được huấn luyện trong môi trường đối nghịch sẽ làm theo ngay. Ngày nay, đội bảo mật OpenAI nhìn nhận vấn đề này theo cách hoàn toàn khác — các cuộc tấn công này ngày càng ít giống hacking hơn, và ngày càng giống social engineering hơn.
Cuộc Tấn Công Thành Công 50% Thời Gian
Một ví dụ được ghi lại từ năm 2025 minh họa mức độ tinh vi của những cuộc tấn công này. Các nhà nghiên cứu bảo mật bên ngoài đã báo cáo một email độc hại được thiết kế đặc biệt để thao túng AI assistant khi thực hiện deep research. Email trông hoàn toàn hợp lệ — chứa các hướng dẫn về xem xét dữ liệu nhân viên, hoàn thiện mô tả vai trò và phối hợp với bộ phận tài chính. Nó được thiết kế để trông đáng tin, không đáng ngờ.
Kết quả: cuộc tấn công thành công khoảng 50% thời gian, ngay cả khi các biện pháp bảo vệ của OpenAI đang hoạt động. Đây không phải lỗi — đây là giới hạn căn bản. Nếu vấn đề không phải là xác định chuỗi ký tự độc hại mà là chống lại nội dung gây hiểu lầm trong ngữ cảnh, thì chỉ lọc đầu vào sẽ không bao giờ đủ.
Tại Sao AI Firewall Không Đủ
"AI firewalling" — các hệ thống phân loại nội dung đến là độc hại hay an toàn trước khi agent nhìn thấy — đã trở thành khuyến nghị phổ biến trong cộng đồng bảo mật. Phân tích của OpenAI thẳng thắn: các cơ chế này gặp khó khăn với các cuộc tấn công phát triển đầy đủ vì cùng lý do các fact-checker gặp khó với thông tin sai lệch. Phát hiện sự lừa dối thường đòi hỏi ngữ cảnh mà bộ phân loại không có.
Hàm ý này rất quan trọng: bạn không thể lọc để thoát khỏi social engineering. Bạn phải thiết kế hệ thống sao cho ngay cả khi thao túng thành công, thiệt hại vẫn được kiểm soát.
Nhìn Nhận Agent Như Nhân Viên
Khung bảo mật của OpenAI đặt AI agent trong hệ thống ba tác nhân — tương tự như một nhân viên chăm sóc khách hàng làm việc thay mặt người sử dụng lao động, trong khi liên tục tiếp xúc với đầu vào từ bên thứ ba có thể cố gắng đánh lừa họ.
Sự tương đồng với hệ thống con người là có chủ đích. Một nhân viên hỗ trợ có quyền hoàn tiền là mục tiêu của social engineering. Các công ty không giải quyết vấn đề này bằng cách huấn luyện phán đoán con người hoàn hảo — họ giới hạn những gì bất kỳ agent nào có thể làm, gắn cờ các mẫu bất thường và xây dựng các biện pháp bảo vệ xác định xung quanh các hành động nguy hiểm nhất. Logic tương tự áp dụng cho AI agent.
Phân Tích Source-Sink và Safe URL
Về mặt kỹ thuật, OpenAI kết hợp khung social engineering này với phân tích source-sink. Mọi kết quả nguy hiểm đều cần hai thứ: một nguồn (cách kẻ tấn công ảnh hưởng đến hệ thống, như trang web độc hại) và một đích (khả năng trở nên nguy hiểm khi bị lạm dụng, như gửi dữ liệu cho bên thứ ba hoặc theo dõi liên kết bên ngoài).
Mẫu tấn công phổ biến nhất chống lại ChatGPT cố gắng thuyết phục assistant trích xuất thông tin nhạy cảm từ cuộc trò chuyện và truyền đến kẻ tấn công. Trong hầu hết các trường hợp được ghi nhận, huấn luyện an toàn khiến agent từ chối. Với các trường hợp không từ chối, OpenAI đã xây dựng Safe URL — cơ chế phát hiện khi thông tin học được trong cuộc trò chuyện sẽ được truyền đến bên thứ ba. Khi kích hoạt, hệ thống hiển thị thông tin đó cho người dùng để xác nhận rõ ràng, hoặc chặn hoàn toàn việc truyền và hướng dẫn agent tìm cách tiếp cận khác.
Biện pháp bảo vệ tương tự mở rộng đến Atlas (điều hướng và bookmark), Deep Research (tìm kiếm và điều hướng), ChatGPT Canvas và ChatGPT Apps — nơi các agent hoạt động trong môi trường sandbox phát hiện các giao tiếp đi bất ngờ và yêu cầu sự đồng ý của người dùng.
Sự Thừa Nhận Thẳng Thắn
Điều làm bài viết này đáng chú ý là sự minh bạch của nó. OpenAI không tuyên bố đã giải quyết được prompt injection. Tỷ lệ thành công tấn công 50% khi phòng thủ đang hoạt động là thừa nhận thẳng thắn rằng đây vẫn là vấn đề chưa được giải quyết. Chiến lược không phải là "ngăn chặn mọi cuộc tấn công" — mà là "đảm bảo rằng khi tấn công thành công, tác động bị giới hạn và người dùng vẫn kiểm soát được."
Đó là tư thế bảo mật trưởng thành. Đó cũng là thừa nhận ngầm rằng khi AI agent có thêm năng lực và tự chủ, kiến trúc bảo mật xung quanh chúng cần mở rộng tương ứng — không chỉ trong huấn luyện mô hình, mà còn trong thiết kế hệ thống, ràng buộc hành động và tính minh bạch hướng đến người dùng.
Nguồn: https://openai.com/vi-VN/index/designing-agents-to-resist-prompt-injection/